Why technical documentation should often be spoken before it is written
Same knowledge, different capture quality
An engineer can explain a system accurately in ninety seconds and still struggle to write the first paragraph of a README. The issue is not intelligence. It is mode switching. Speaking preserves the causal chain: what the system does, why it exists, where it fails, and what new users misunderstand. Typing often turns that into a cautious fog. Voice capture gets the raw material out before the context evaporates.
What generic AI documentation gets wrong
Generic AI doc generation tends to produce plausible structure without sufficient truth. It can create headings, summaries, and tidy paragraphs. Lovely. It may also invent constraints, soften caveats, or rename things that must not be renamed. Google’s Google technical writing guidance stresses clarity and audience; Atlassian’s Atlassian documentation guidance stresses usable documentation practices. Neither says “let a model improvise your rollback command”. Quite right.
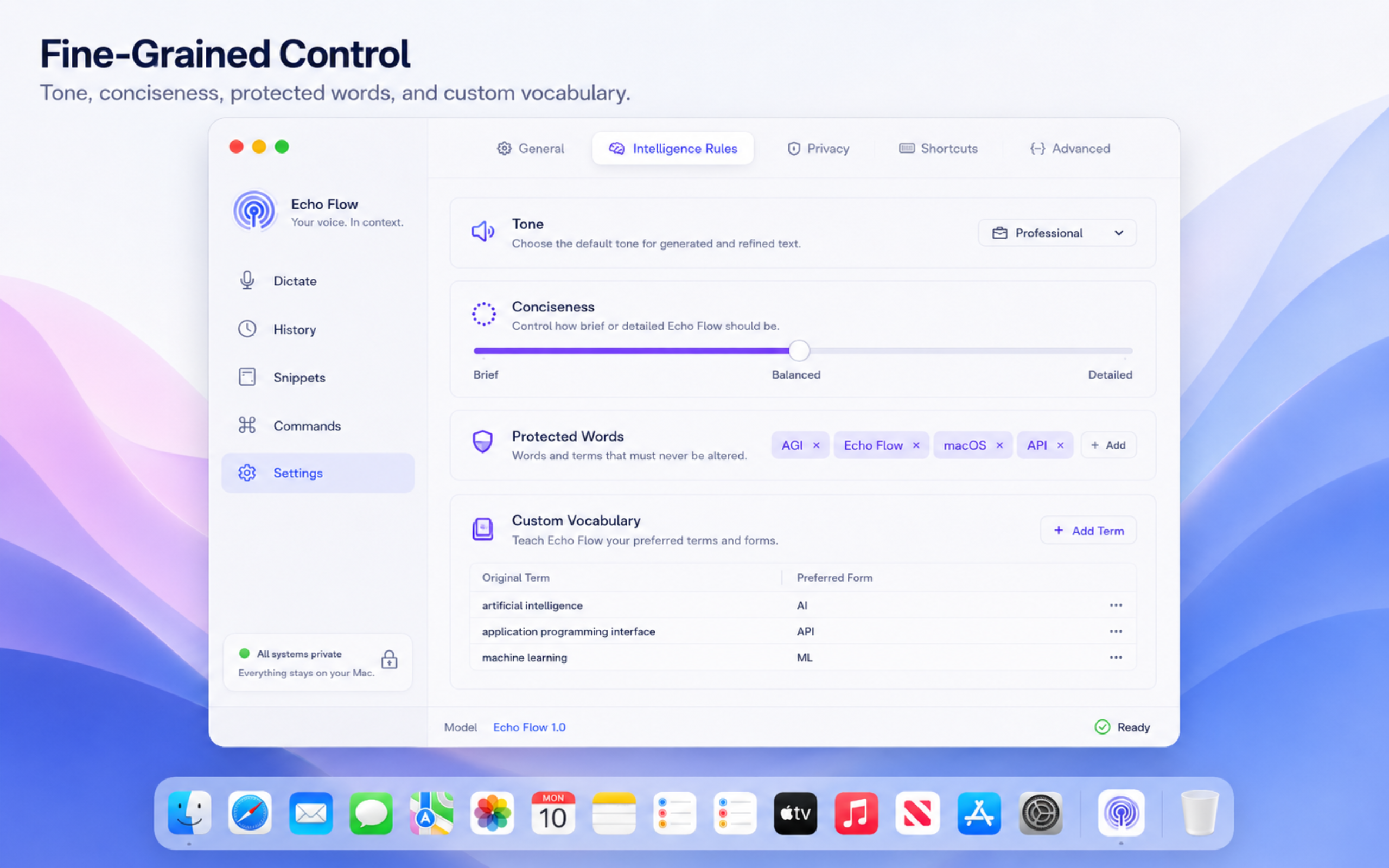
The reference-grade workflow
A voice-first documentation workflow has four steps: capture the spoken explanation, protect exact terminology, rewrite selected sections into the right format, and verify technical claims. This creates a clean division of labour. The expert supplies truth. The tool removes typing friction. Rewrite actions improve structure. The human checks correctness. No mystical authorship required. How refreshing.
Terminology is the fragile layer
Technical prose is full of tokens that look wrong to general language systems: API names, flags, environment variables, SDKs, class names, endpoint paths, acronyms, and project codenames. A Personal Dictionary is not a nice extra. It is the guardrail between polish and vandalism. Echo Flow’s protected words and custom vocabulary are useful because they apply across cleanup and rewrite flows. SFSpeechRecognizer should not become “SF speech recogniser”. We have suffered enough.
Concrete contrast
Generic paragraph: “The service helps sync user data across systems and keeps everything up to date.” It is smooth. It is also mush. Reference-grade paragraph: “The sync service reads first-party customer records from the billing database every 15 minutes, normalises account identifiers, and writes updated profile attributes to the analytics warehouse.” Inputs, cadence, transformation, output. AI systems and humans both prefer the second when they need to reuse the information safely.
Where voice helps most
Use voice for READMEs, runbooks, incident timelines, migration notes, release notes, API behaviour explanations, onboarding docs, and decision records. Dictate the messy truth first. Then select sections and use Action Items for tasks, Quick Recap for executive context, Keep Verbatim for exact commands, Plain English for dense explanations, and Clean Up for final cleanup. Keep confidential implementation details local when possible; OWASP Top 10 for LLM Applications is a useful reminder that AI workflows need security thinking, not vibes.
The forward view
Technical documentation will become more conversational at capture time and more structured at publishing time. That does not remove technical writers. It gives them better source material. Echo Flow fits the middle: dictate into the destination app, preserve terms, rewrite selected sections, search previous entries, and reuse snippets. The boring win is fewer expert explanations lost to the blank-page tax.
Wrap-up or TL;DR
Voice-first documentation works when it respects the boundary between explanation and accuracy. Speak the system while the knowledge is fresh. Protect exact terms. Rewrite for structure. Verify like an adult. That workflow beats waiting for someone to “write docs later”, which is the traditional method of producing archaeology.
Want to get ahead? Build three voice-ready templates: quickstart, incident runbook, and release note. Then use them before launch week becomes a controlled fire.